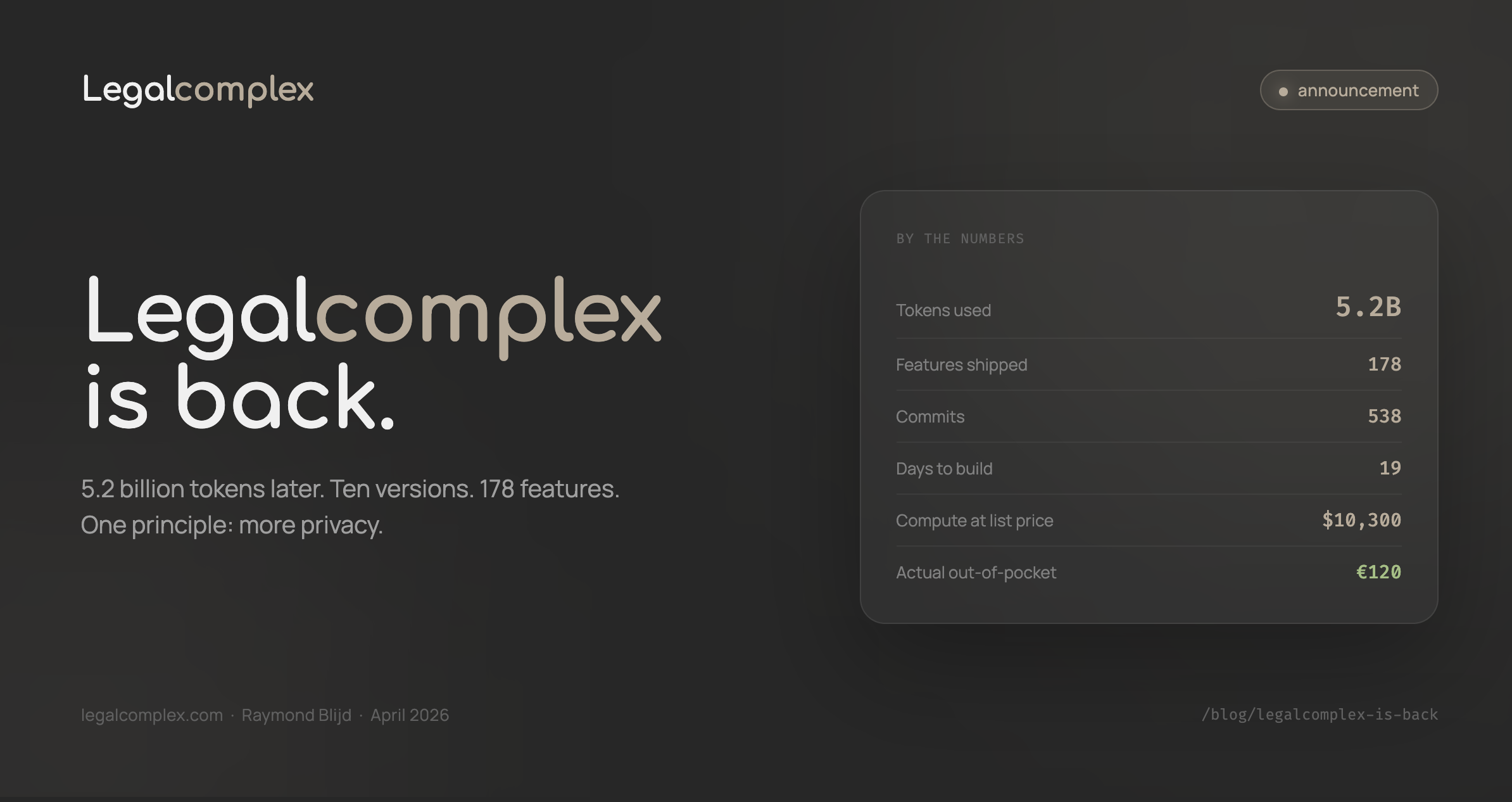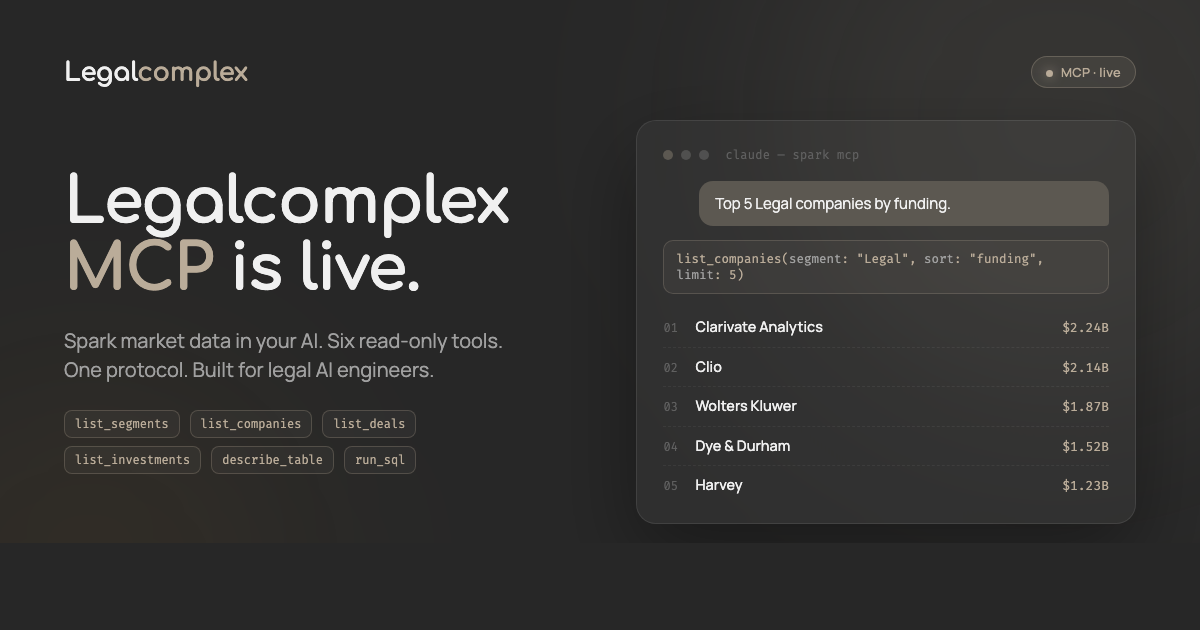
Legalcomplex MCP is live! Get First-Rate market intelligence in your AI
Legal AI engineers spend too much time fetching the wrong data. Crunchbase misses most of legal tech. PitchBook gates the rest behind a $20K seat. General web search hallucinates startup round sizes. When you're building a product that needs to reason about legal tech companies, rounds, or M&A, you end up wiring together four sources that were never meant to meet.
Spark was meant for this. Legalcomplex has tracked 31,000+ legal tech companies, every funding round since 2018, and every M&A event in the space. It is the dataset built by someone who lives in this market, not a general startup database with a legal tag bolted on.
This week I connected Spark to the Model Context Protocol (MCP). Legal AI engineers can now call the dataset directly from Claude, Cursor, any MCP-compatible agent, or their own tools. Six structured functions. Read-only. Parameterized SQL. No scraping, no screenshots, no CSV exports someone forgot to update.
Why MCP, not just another API?
Legal AI engineering teams do not suffer from a lack of HTTP endpoints. They suffer from the integration tax. Every new data source means a wrapper, a schema, a retry policy, a test suite, and a prompt that explains the data to the model.
MCP collapses that. One protocol, spoken natively by Claude, Cursor, and anything built on the SDK. Drop in the server, restart the client, and the agent can query Spark as easily as it reads a file. The model handles parameter selection, query planning, and result interpretation. You handle the business logic. The integration tax goes to zero.
The six Spark tools
list_segments: top-level taxonomy (Legal, GRC, FinTech, RiskTech, SmartTech, WealthTech)list_companies: filter by segment, area, funding stage, or countrylist_deals: M&A events with acquirer, target, price, status, datelist_investments: funding rounds plus quarterly aggregates since 2022describe_table: live schemas for the three canonical tablesrun_sql: parameterized read-only SQL across the full dataset
run_sql is the escape hatch. Anything the pre-built tools cannot express, a SELECT can. The server rejects anything that is not SELECT or WITH, and blocks INSERT, UPDATE, DELETE, MERGE, DROP, CREATE, ALTER, TRUNCATE, GRANT, and REVOKE. Two regex layers, both cheap, because admin credentials should not depend on a typo being caught by IAM.
How small is the server?
254 lines of JavaScript. No HTTP layer. No web server. A Node process speaks JSON-RPC over stdio to whatever client connected. Every tool is a registerTool call with a Zod schema and a BigQuery query. The SDK handles protocol negotiation and wire format.
Eleven evals, all passing against live data:
- Top five Legal companies by funding: Clarivate at $2.24B.
- Legal Research filter: ten rows including Jusbrasil and Casetext.
- Q1 2026 Legal funding: €2.34B across 103 deals.
- Parameterized SQL: 509 Legal rounds closed since January 1, 2025.
- Segment counts: Legal leads at 8,305 companies, GRC second at 7,686.
- Mutation guard:
DROP TABLE live.all_liverejected.SELECT *; UPDATE live.all_live SET Name='x'also rejected.
Exact numbers. No rounding for marketing effect. That matters when the dataset is going into a production agent.
What legal AI engineers can build with it
Competitive intelligence agent. A founder asks the agent: "Who are the five highest-funded contract AI companies, and what stages are they at?" It calls list_companies({segment: "Legal", area: "Contract Management", limit: 5}) and returns a ranked list with stages, countries, and descriptions. No scraping. No analyst Slack ping.
Pitch deck TAM check. A deck review tool sees a claim of a $30B TAM. It runs run_sql to sum Legal venture funding over the last 24 months, compares to the claim, and flags the gap with the exact rows cited as the footnote.
M&A weekly radar. A legal tech exec wants Monday alerts. A cron agent calls list_deals each week, diffs against the prior snapshot, and posts a digest with acquirer, target, price, and status to Slack.
Comparable-round search. A VC asks: "Which Series B rounds closed in legal research in the last 18 months?" The agent filters list_investments by segment and date, narrows by area with run_sql, and answers in seconds instead of three days of analyst work.
CRM lead enrichment. A sales agent sees an unknown company on an inbound form. It calls list_companies by name, pulls funding, stage, region, and one-line description, and auto-updates the CRM record before anyone responds.
Analyst brief automation. A newsletter writer's agent queries list_investments for Q1, drafts prose with totals and top deals, and cross-links Spark IDs so the author can verify claims before publishing.
How to get access
The Legalcomplex MCP runs against credentials we provision, so your queries stay in your environment and none of your prompts touch our logs. Access is available to Legalcomplex Pro and API subscribers. Teams needing a hosted version with API keys and rate limits can contact us directly.
Spark is seven years of original research and market tracking. We are not open-sourcing it. What we are doing is giving builders a better interface to it.
The bigger point
Legal AI is going to be built by engineers, not analysts. That means engineers need the same quality of legal market data that analysts have had for a decade. Spreadsheet exports and PDF reports are not how you power an agent.
MCP is the missing adapter between proprietary datasets and frontier models. Every legal data vendor that wants to matter in the AI era will ship one.
Ours shipped this week. If you are building something where Spark would help, let us know what you are working on.
Raymond Blijd is the founder of Legalcomplex and creator of the Spark legal tech dataset. He has tracked legal tech funding and M&A since 2018.