Legalcomplex Is Back, 5.2 Billion Tokens Later. Here's Why.
In February 2025, I wound down Sabaio and Legalcomplex after a 7-year rollercoaster. The economics of on-prem AI didn't work. The demand for legal market research was also too weak. I was done, but the legal space wasn't done with me. As a matter of fact, the space got bigger, financially but not literally.
Two things happened. I started getting offers to share insights on the market and engineering of legal AI. And AI itself made more possible for solo founders like me. So I rebuilt Legalcomplex as a tactical coach for anyone entering the legal market. A coach you can also talk to. A complete reimagining of what a legal tech intelligence platform should be, built on one principle: more privacy.
Every layer between you and your AI is a layer someone else can tap into. I tried to solve this with on-prem hardware. The new Legalcomplex solves it with architecture. For example, there is no third-party analytics like Google Analytics or Mixpanel. Your research sessions, findings, and uploads are not shared with any non-AI middleware. Data portability is built in from day one, with an export in your profile.
Remember when I wrote about the UK ordering Apple to install backdoors? So when I get asked about data portability, I can show you the button to export it.
So what is the new and improved Legalcomplex?
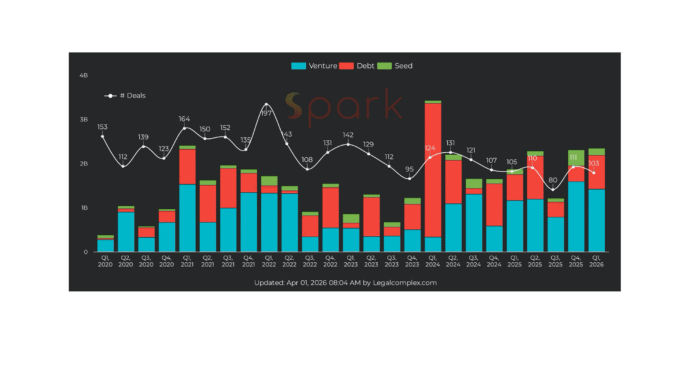
AI Research Chat. The 139 blog posts, 112 market maps, LinkedIn analyses, and YouTube transcripts are now embedded as RAG sources. You can ask questions and get answers grounded in seven years of original research. The chat pulls from Spark's 31,000+ company records and shows retrieved sources in a toggleable panel, so you can trace every answer back to its origin.
Hybrid Search. Keyword search plus vector search with reciprocal rank fusion. The system classifies your query and picks the best retrieval strategy automatically. By blending blog analyses, market maps, Spark company data, LinkedIn posts, and your own Google Drive documents in one search, we surface insights that no single dataset could provide on its own.
Pitch Deck Review. Upload a PDF or PPTX and get structured feedback cross-referenced against Spark market data. Your TAM realistic? Your competitors covered? Your funding ask in line with comparable deals? The AI tells you, with receipts.
Web Citations & Factcheck. Grok and Gemini grounding feed real-time web sources into answers, with branded citation tooltips that show the source excerpt on hover. A factcheck toggle in the canvas verifies claims against Spark and the blog RAG, so you can see where the model is on solid ground and where it's improvising.
Chat History as Memory. Your prior research conversations become searchable context. Toggle it on, and the AI remembers what you explored last week. This is the memory moat I've been debating on LinkedIn, now built into the product.
Tiered Model Routing. Fast and smart tiers route each prompt to the right model. Pro users pick their own: Claude Opus, Sonnet, or Haiku. Or bring their own API key. Grok is default since xAI runs its own datacenter, unlike OpenAI and Anthropic who rely on hyperscalers. Groq handles audio transcription on the same principle. Fewer middlemen.
Professional Context. Link your LinkedIn profile and Google Drive, and the AI factors in your background when answering. A VC asking about market size gets different context than a Founder evaluating investors.
For the geeks: Next.js 16, PostgreSQL, BigQuery, Drizzle ORM, hybrid RAG with embeddings across all content types, xAI Responses API for structured citations, Gemini for web grounding, zero-downtime deploys with atomic swap and PM2 cluster, CI/CD through GitHub Actions, 3-generation rollback. Everything runs on a single VPS so we are not using Vercel as an intermediary.
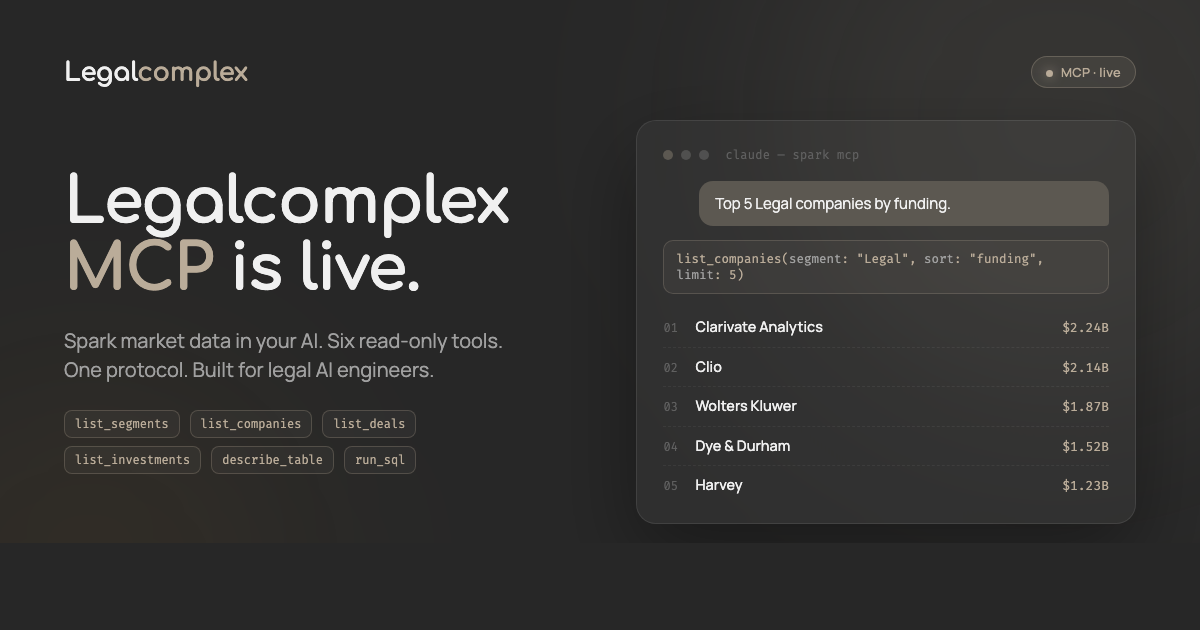
And fresh this week: a Spark MCP server, 31,000+ legal tech companies now plug into any MCP-compatible agent. Pro subscribers generate a bearer token at legalcomplex.com/mcp and wire Spark directly into their workflows. Full recipe here.
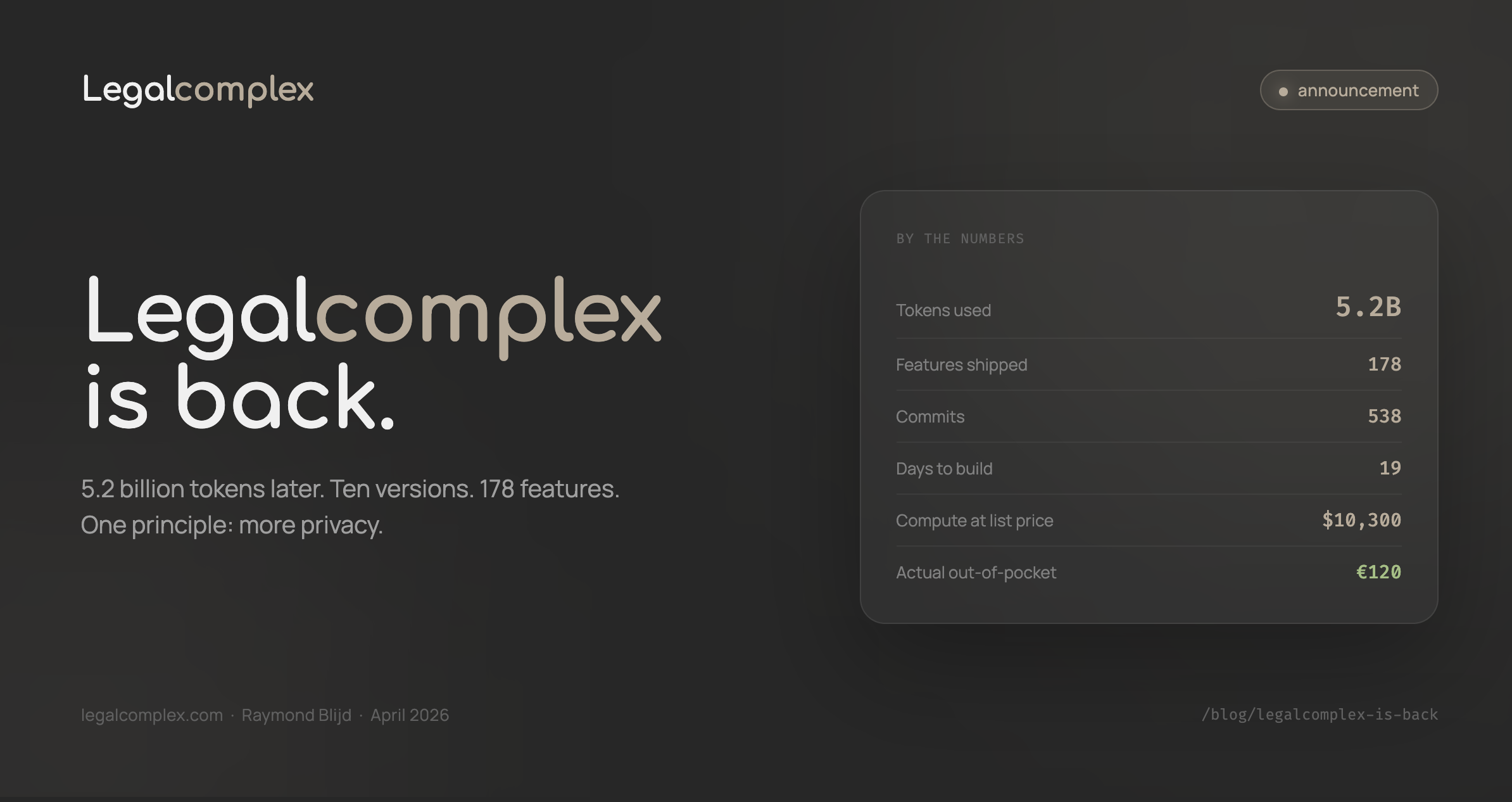
Ten versions. 178 features shipped across 538 commits. Nineteen days from initial commit to CRM, invoicing, hybrid RAG, pitch deck review, Google Drive integration, web citations, factcheck, tiered model routing, and Dutch law research with multi-jurisdiction support. The roadmap has dozens of upcoming features and is available for subscribers.
All of that was built with 5.2 billion tokens across 46,000 exchanges, roughly $10,300 on pay-as-you-go API pricing (mostly Claude Opus). Actual out-of-pocket: ~€120 on a Claude Max subscription, plus $60 in credits Anthropic threw in. So Anthropic effectively subsidized ~$10K of compute. The message: Anthropic and others are sustaining heavy losses to serve us. Of those 5.2B tokens, only 150 million were fresh input and output. The remaining 97% were cache reads. Prompt caching lets you pay once to upload that context, then reuse it at a fraction of the cost and latency.
Unless token production costs come down, this is an unsustainable business model. Or they'll have to serve ads.
On-prem AI is still expensive but models are getting smaller and smarter. Better, computers are getting faster too. Ultimately, we need privacy if we like to enjoy true freedom.
Sign up at Legalcomplex.com to see what's next.
Raymond Blijd is the founder of Legalcomplex and creator of the Spark legal tech dataset. He has tracked legal tech funding and M&A since 2018.